Si je comprends bien, les évaluations de livre sur une échelle de 1 à 5 sont des scores de Likert. C'est-à-dire qu'un 3 pour moi peut ne pas être nécessairement un 3 pour quelqu'un d'autre. C'est une échelle ordinale IMO. Il ne faut pas vraiment utiliser les échelles ordinales mais bien prendre le mode, la médiane et les centiles.
Alors, est-il «acceptable» de contourner les règles, car la grande partie de la population comprend des moyens supérieurs aux statistiques ci-dessus? Bien que les chercheurs s'opposent vivement à la moyenne des données de l'échelle de Likert, est-il acceptable de le faire avec les masses (pratiquement)? Est-ce que prendre la moyenne dans ce cas est même trompeur pour commencer?
Il semble peu probable qu'une entreprise comme Amazon tâtonne les statistiques de base, mais sinon, que manque-t-il ici? Peut-on prétendre que l'échelle ordinale est une approximation commode de l'ordinal pour justifier de prendre la moyenne? Sur quels motifs?
la source
Réponses:
Avantages de l’utilisation de la moyenne pour résumer la tendance centrale d’une note de 5 points
Comme @gung l'a mentionné, je pense qu'il y a souvent de très bonnes raisons de considérer la moyenne d'un élément en cinq points comme un indice de tendance centrale. J'ai déjà exposé ces raisons ici .
Paraphraser:
Pourquoi la moyenne est bonne pour Amazon
Pensez aux objectifs d'Amazon en rapportant la moyenne. Ils pourraient viser à
Amazon fournit une sorte de moyenne arrondie, des comptes de fréquence pour chaque option de classement et la taille de l’échantillon (c’est-à-dire le nombre de classements). Cette information est probablement suffisante pour permettre à la plupart des gens d’apprécier à la fois le sentiment général à l’égard de cet élément et la confiance qu’il en a (un score de 4,5 sur 20 a plus de chances d’être précis que sur un 4,5 à 2; un élément de 10 5 -étoiles, et une étoile avec aucun commentaire pourrait encore être un bon article).
Vous pourriez même voir la moyenne comme une option démocratique. De nombreuses élections sont décidées en fonction du candidat qui obtient la moyenne la plus élevée sur une échelle de deux points. De même, si vous prenez l'argument que chaque personne qui soumet une révision obtient un vote, vous pouvez voir la moyenne comme un formulaire qui pondère également le vote de chaque personne.
Les différences d'échelle d'utilisation posent-elles vraiment un problème?
Il existe un large éventail de biais de notation connus dans la littérature psychologique (pour une revue, voir Saal et al 1980), tels que le biais de tendance centrale, le biais de clémence, le biais de stricte. En outre, certains évaluateurs seront plus arbitraires et d’autres plus fiables. Certains peuvent même mentir systématiquement en donnant de faux commentaires positifs ou négatifs. Cela créera diverses formes d'erreur en essayant de calculer le classement moyen réel d'un élément.
Cependant, si vous preniez un échantillon aléatoire de la population, de tels biais disparaîtraient et, avec un échantillon de taille suffisant des évaluateurs, vous obtiendriez tout de même la vraie moyenne.
Bien sûr, vous n’obtenez pas un échantillon aléatoire sur Amazon, et il existe un risque que l’ensemble des évaluateurs que vous obtenez pour un article soit systématiquement biaisé pour être plus clément ou strict, et ainsi de suite. Cela dit, je pense que les utilisateurs d'Amazon apprécieraient que les évaluations soumises par les utilisateurs proviennent d'un échantillon imparfait. Je pense aussi qu'il est très probable qu'avec un échantillon de taille raisonnable, dans la plupart des cas, la majorité des différences de biais de réponse commenceraient à disparaître.
Avancées possibles au-delà de la moyenne
En ce qui concerne l’amélioration de la précision de la notation, je ne remettrais pas en cause le concept général de la moyenne, mais je pense plutôt qu’il existe un autre moyen d’estimer la moyenne réelle de la population pour un article un grand échantillon représentatif a-t-il été invité à évaluer l'élément).
Ainsi, si l'exactitude de la notation était l'objectif principal d'Amazon, je pense qu'elle devrait s'efforcer d'augmenter le nombre de notations par élément et adopter certaines des stratégies ci-dessus. De telles approches pourraient être particulièrement pertinentes lors de la création d'un classement "best-of". Cependant, pour la modeste note de la page, il se pourrait bien que la signification de l'échantillon réponde mieux aux objectifs de simplicité et de transparence.
Références
la source
Pour être un peu technique ici, ces évaluations ne sont pas réellement une échelle de Likert ; ce sont juste des cotes ordinales. Cela dit, votre argument est essentiellement correct. Cependant, je pense souvent que l'on en fait trop. Une chose à noter est qu'il est généralement compris que la moyenne d'un nombre d'éléments ordinaux peut être d'environ un intervalle. Ainsi, lorsqu'il y a plusieurs notations, la moyenne devient une représentation plus raisonnable. J'ai trouvé cette réponse de @JeromyAnglim excellente (vraiment, la question et toutes les réponses suivantes méritent d'être lues). Pour un traitement plus théorique, voir ici. Sur une note différente, j'aime bien Amazon, mais je ne vois aucune raison de s'attendre à une sophistication statistique de leur part, en particulier en termes de conception de site de base - le but est la convivialité pour les consommateurs, pas pour impressionner les professeurs.
la source
Tout le monde a de bonnes opinions à ce sujet. Je ne pense pas vraiment pouvoir ajouter beaucoup plus. Cependant, je vais poster ceci :
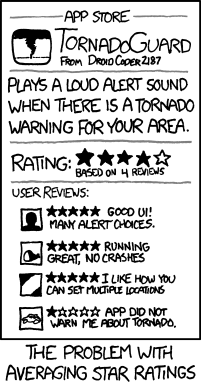
la source
D'après mon expérience, la moyenne des données d'échelle de cotation est souvent la corrélation la plus étroite avec le niveau de métriques du monde réel que nous essayons d'associer à l'échelle de cotation. Nous avons trouvé beaucoup de relations linéaires et la moyenne est donc l'un des meilleurs moyens de résumer les données. Ceci étant dit, comme Jeromy l'a fait remarquer, la plupart des méthodes d'analyse de la tendance centrale d'une échelle d'évaluation donnent des résultats similaires (ordres de classement, etc.) la plupart du temps.
De plus, je soupçonne qu’Amazon n’est probablement pas si préoccupé par la validité scientifique d’une manière ou d’une autre. En fin de compte, l'objectif d'Amazon est d'inciter les internautes à magasiner davantage sur Amazon.com, et la façon dont les revues contribuent à atteindre cet objectif ne variera probablement pas selon le récapitulatif à un chiffre utilisé. Les bons produits seront récompensés, les très mauvais produits punis et les acheteurs nerveux auront la possibilité d'examiner plus en détail les avantages et les inconvénients.
la source
Les notations d'Amazon sont trompeuses en raison des sociétés qui jouent avec le système. Lorsque des remises et des produits gratuits sont proposés aux clients en échange d’évaluations 5 étoiles, les «statistiques» relatives au nombre ou aux notations d’évaluations deviennent sans objet.
la source
Vous faites un bon point. Prendre la moyenne des nombres ordinaux est quelque peu trompeur. N'importe quel résumé de plusieurs classements souffrirait du fait que mon subjectif 3 peut vraiment correspondre à votre 4. Donc, combiner différents scores individuels est probablement le plus gros problème. Interpréter la moyenne d'un 3 et d'un 4 comme 3,5 n'est pas aussi flagrant.
la source