Cette question découle de ma confusion réelle sur la façon de décider si un modèle logistique est assez bon. J'ai des modèles qui utilisent l'état des couples projet individuel deux ans après leur formation en tant que variable dépendante. Le résultat est réussi (1) ou non (0). J'ai des variables indépendantes mesurées au moment de la formation des paires. Mon objectif est de tester si une variable qui, selon moi, influencerait le succès des paires a un effet sur ce succès, en contrôlant d'autres influences potentielles. Dans les modèles, la variable d'intérêt est significative.
Les modèles ont été estimés à l'aide de la glm()fonction dans R. Pour évaluer la qualité des modèles, j'ai fait quelques choses: glm()vous donne le residual deviance, le AICet le BICpar défaut. De plus, j'ai calculé le taux d'erreur du modèle et tracé les résidus groupés.
- Le modèle complet a une déviance résiduelle plus petite, AIC et BIC que les autres modèles que j'ai estimés (et qui sont imbriqués dans le modèle complet), ce qui m'amène à penser que ce modèle est "meilleur" que les autres.
- Le taux d'erreur du modèle est assez faible , à mon humble avis (comme dans Gelman et Hill, 2007, pp.99 ) :,
error.rate <- mean((predicted>0.5 & y==0) | (predicted<0.5 & y==1)aux alentours de 20%.
Jusqu'ici tout va bien. Mais lorsque je trace le résidu de la poubelle (toujours à la suite des conseils de Gelman et Hill), une grande partie des bacs se situent en dehors de l'IC à 95%:
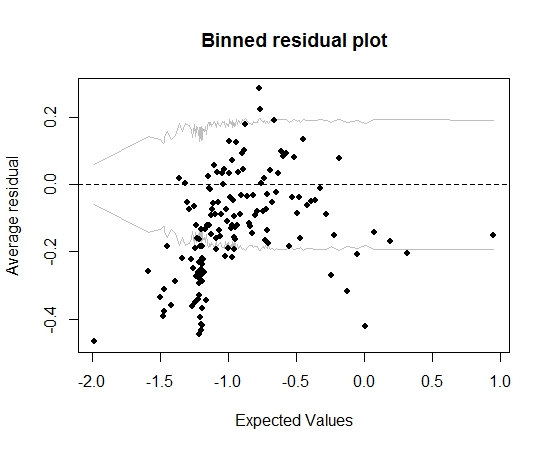
Cette intrigue m'amène à penser qu'il y a quelque chose de complètement faux dans le modèle. Cela devrait-il m'amener à jeter le modèle? Dois-je reconnaître que le modèle est imparfait mais le conserver et interpréter l'effet de la variable d'intérêt? J'ai joué avec l'exclusion des variables à leur tour, et aussi une certaine transformation, sans vraiment améliorer le tracé des résidus groupés.
Éditer:
- À l'heure actuelle, le modèle comporte une douzaine de prédicteurs et 5 effets d'interaction.
- Les couples sont "relativement" indépendants les uns des autres dans le sens où ils se forment tous sur une courte période (mais pas à proprement parler, tous simultanément) et qu'il y a beaucoup de projets (13k) et beaucoup d'individus (19k ), donc une bonne partie des projets ne sont rejoints que par une seule personne (il y a environ 20000 paires).
la source
Réponses:
La précision de la classification (taux d'erreur) est une règle de notation incorrecte (optimisée par un modèle bidon), arbitraire, discontinue et facile à manipuler. Ce n'est pas nécessaire dans ce contexte.
Vous n'avez pas indiqué le nombre de prédicteurs. Au lieu d'évaluer l'adéquation du modèle, je serais tenté de simplement adapter le modèle. Une approche de compromis consiste à supposer que les interactions ne sont pas importantes et à permettre aux prédicteurs continus d'être non linéaires à l'aide de splines de régression. Tracez les relations estimées. le
rmspackage en R rend tout cela relativement facile. Voir http://biostat.mc.vanderbilt.edu/rms pour plus d'informations.Vous pourriez élaborer sur les «paires» et si vos observations sont indépendantes.
la source
La situation semble un peu étrange, mais je pense que votre intrigue peut fournir un indice. Il semble qu'il puisse y avoir une relation curviligne. Il est permis d'utiliser des termes polynomiaux et d'autres transformations de variables prédictives (par exemple,X2 ) en régression logistique, tout comme en régression OLS. Cela pourrait valoir la peine d'essayer.
la source