Étant donné un nombre positif , trouver le nombre d' alcanes avec n atomes de carbone, en ignorant les stéréoisomères ; ou de manière équivalente, le nombre d'arbres sans étiquette avec n nœuds, de sorte que chaque nœud a un degré ≤ 4 .
Il s'agit de la séquence OEIS A000602 .
Voir aussi: Paraffines - Rosetta Code
Exemple
Pour , la réponse est , car l' heptane a neuf isomères :
- Heptane :

- 2-méthylhexane :

- 3-méthylhexane :

- 2,2-diméthylpentane :

- 2,3-diméthylpentane :

- 2,4-diméthylpentane :

- 3,3-diméthylpentane :
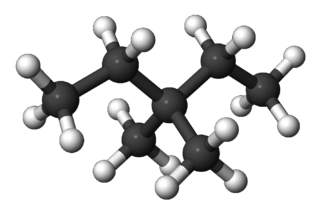
- 3-éthylpentane :


Notez que le 3-méthylhexane et le 2,3-diméthylpentane sont chiraux , mais nous ignorons les stéréoisomères ici.
Cas de test
intput output
=============
0 1
1 1
2 1
3 1
4 2
5 3
6 5
7 9
8 18
9 35
10 75
11 159
12 355
13 802
14 1858
15 4347
16 10359
17 24894
18 60523
19 148284
20 366319
code-golf
sequence
combinatorics
chemistry
alephalpha
la source
la source
Réponses:
CJam (
100 98 91 8983 octets)Prend l'entrée de stdin, les sorties vers stdout. Notez que cela exploite la licence pour ne pas gérer les entrées
0pour économiser deux octets en insérant les définitions deCetD. Démo en ligneNB c'est très lent et peu efficace en mémoire. En réduisant les tableaux, une version beaucoup plus rapide est obtenue (3 octets de plus). Démo en ligne .
Dissection
OEIS donne (modulo une erreur d'indexation) la décomposition de la fonction génératriceA 000598 ( x )A 000678 ( x )A 000599 ( x )A 000602 ( x )====1 + x Z( S3; A 000598 ( x) )x Z(S4; A 000598 ( x ) )Z(S2; A 000598 ( x ) - 1 )A 000678 ( x ) - A 000599 ( x ) + A 000598 ( x2) Z( Sn; F( x ) ) désigne l'indice de cycle du groupe symétrique Sn appliqué à la fonction F( x ) .
J'ai manipulé cela dans une décomposition légèrement golfeur, puis j'ai recherché les séquences intermédiaires et découvert qu'elles se trouvent également dans OEIS:
Les versions antérieures réutilisaient le bloc
C(convolve deux polynômes) de cette réponse . J'en ai trouvé une beaucoup plus courte, mais je ne peux pas mettre à jour cette réponse car elle provient d'une question de chaînage.la source
Node.js 11.6.0 ,
229 223 221218 octetsDérivé de l'implémentation Java suggérée sur Rosetta Code .
Essayez-le en ligne!
la source
Alchimiste (1547 octets)
Démo en ligne .
Remarque: c'est assez lent. Si vous testez avec un interpréteur qui prend en charge l'application d'une règle plusieurs fois à la fois (par exemple la mienne - bien que assurez-vous que vous disposez de la dernière version qui corrige un bogue dans l'analyseur), vous pouvez obtenir une accélération significative en ajoutant deux règles:
qui alignent un itinéraire à travers les règles existantes
Dissection partielle
À un niveau élevé, cela utilise la même approche que ma réponse CJam.
Le modèle de calcul d'Alchemist est essentiellement la machine à registres Minsky . Cependant, Alchemist expose très bien l'équivalence du code et des données, et en autorisant de nombreux jetons sur le côté gauche d'une règle de production, l'état n'est pas contraint d'être représenté par un atome: nous pouvons utiliser un tuple d'atomes, et cela autorise les sous-programmes (non récursifs). Ceci est très utile pour le golf. Les seules choses qui manquent vraiment sont les macros et le débogage.
Pour les tableaux, j'utilise une fonction de couplage qui peut être implémentée de manière assez golfique dans les RM. Le tableau vide est représenté par0 et le résultat du pré-paiement X mettre en réseau UNE est ( 2 A + 1 ) 2X . Il existe un sous-programme à associer: le sous-programme est appelé
Pet il ajoute la valeur deeàb. Il existe deux sous-routines àndissocier : les dissociationsbdeeetb; ettdissociedverseetd. Cela m'a permis d'économiser pas mal de données mélangées entre les variables, ce qui est important: une seule opération de "déplacement"s'étend à au moins 17 octets:
où
Sest l'état actuel etTl'état suivant. Une "copie" non destructive est encore plus coûteuse, car elle doit être effectuée comme un "déplacement" deaversbet un auxiliairetmp, suivi d'un "déplacement" detmpretour versa.Obfuscation
Je me suis aliasé diverses variables et j'ai éliminé environ 60 états dans le processus de golf du programme, et beaucoup d'entre eux n'avaient pas de noms particulièrement significatifs de toute façon, mais pour le jouer pleinement, j'ai écrit un minimiseur afin que les noms soient maintenant complètement indéchiffrables. Bonne chance en ingénierie inverse! Voici le minimiseur (dans CJam), qui fait quelques hypothèses sur le code mais pourrait être adapté pour minimiser d'autres programmes Alchemist:
la source
Pari / GP , 118 octets
Une traduction directe de Peter Taylor de réponse CJAM .
Essayez-le en ligne!
la source