Dans les écoles du monde entier, les enfants tapent un nombre dans leur calculatrice LCD, le retournent et éclatent de rire après avoir créé le mot «Boobies». Bien sûr, c'est le mot le plus populaire, mais il existe de nombreux autres mots qui peuvent être produits.
Cependant, tous les mots doivent contenir moins de 10 lettres (le dictionnaire contient cependant des mots longs, vous devez donc effectuer un filtre dans votre programme). Dans ce dictionnaire, il y a des mots en majuscules, donc convertissez tous les mots en minuscules.
À l'aide d'un dictionnaire de langue anglaise, créez une liste de chiffres qui peuvent être saisis dans une calculatrice LCD et faire un mot. Comme pour toutes les questions de code de golf, le programme le plus court pour terminer cette tâche gagne.
Pour mes tests, j'ai utilisé la liste de mots UNIX, recueillie en tapant:
ln -s /usr/dict/words w.txt
Ou bien, obtenez-le ici .
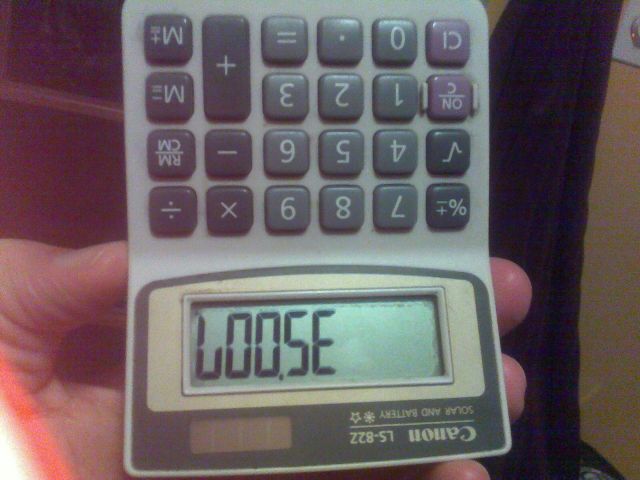
Par exemple, l'image ci-dessus a été créée en tapant le nombre 35007dans la calculatrice et en le retournant.
Les lettres et leurs numéros respectifs:
- b :
8 - g :
6 - l :
7 - je :
1 - o :
0 - s :
5 - z :
2 - h :
4 - e :
3
Notez que si le nombre commence par un zéro, un point décimal est requis après ce zéro. Le nombre ne doit pas commencer par un point décimal.
Je pense que c'est le code de MartinBüttner, je voulais juste vous en remercier :)
/* Configuration */
var QUESTION_ID = 51871; // Obtain this from the url
// It will be like http://XYZ.stackexchange.com/questions/QUESTION_ID/... on any question page
var ANSWER_FILTER = "!t)IWYnsLAZle2tQ3KqrVveCRJfxcRLe";
/* App */
var answers = [], page = 1;
function answersUrl(index) {
return "http://api.stackexchange.com/2.2/questions/" + QUESTION_ID + "/answers?page=" + index + "&pagesize=100&order=desc&sort=creation&site=codegolf&filter=" + ANSWER_FILTER;
}
function getAnswers() {
jQuery.ajax({
url: answersUrl(page++),
method: "get",
dataType: "jsonp",
crossDomain: true,
success: function (data) {
answers.push.apply(answers, data.items);
if (data.has_more) getAnswers();
else process();
}
});
}
getAnswers();
var SIZE_REG = /\d+(?=[^\d&]*(?:<(?:s>[^&]*<\/s>|[^&]+>)[^\d&]*)*$)/;
var NUMBER_REG = /\d+/;
var LANGUAGE_REG = /^#*\s*([^,]+)/;
function shouldHaveHeading(a) {
var pass = false;
var lines = a.body_markdown.split("\n");
try {
pass |= /^#/.test(a.body_markdown);
pass |= ["-", "="]
.indexOf(lines[1][0]) > -1;
pass &= LANGUAGE_REG.test(a.body_markdown);
} catch (ex) {}
return pass;
}
function shouldHaveScore(a) {
var pass = false;
try {
pass |= SIZE_REG.test(a.body_markdown.split("\n")[0]);
} catch (ex) {}
return pass;
}
function getAuthorName(a) {
return a.owner.display_name;
}
function process() {
answers = answers.filter(shouldHaveScore)
.filter(shouldHaveHeading);
answers.sort(function (a, b) {
var aB = +(a.body_markdown.split("\n")[0].match(SIZE_REG) || [Infinity])[0],
bB = +(b.body_markdown.split("\n")[0].match(SIZE_REG) || [Infinity])[0];
return aB - bB
});
var languages = {};
var place = 1;
var lastSize = null;
var lastPlace = 1;
answers.forEach(function (a) {
var headline = a.body_markdown.split("\n")[0];
//console.log(a);
var answer = jQuery("#answer-template").html();
var num = headline.match(NUMBER_REG)[0];
var size = (headline.match(SIZE_REG)||[0])[0];
var language = headline.match(LANGUAGE_REG)[1];
var user = getAuthorName(a);
if (size != lastSize)
lastPlace = place;
lastSize = size;
++place;
answer = answer.replace("{{PLACE}}", lastPlace + ".")
.replace("{{NAME}}", user)
.replace("{{LANGUAGE}}", language)
.replace("{{SIZE}}", size)
.replace("{{LINK}}", a.share_link);
answer = jQuery(answer)
jQuery("#answers").append(answer);
languages[language] = languages[language] || {lang: language, user: user, size: size, link: a.share_link};
});
var langs = [];
for (var lang in languages)
if (languages.hasOwnProperty(lang))
langs.push(languages[lang]);
langs.sort(function (a, b) {
if (a.lang > b.lang) return 1;
if (a.lang < b.lang) return -1;
return 0;
});
for (var i = 0; i < langs.length; ++i)
{
var language = jQuery("#language-template").html();
var lang = langs[i];
language = language.replace("{{LANGUAGE}}", lang.lang)
.replace("{{NAME}}", lang.user)
.replace("{{SIZE}}", lang.size)
.replace("{{LINK}}", lang.link);
language = jQuery(language);
jQuery("#languages").append(language);
}
}body { text-align: left !important}
#answer-list {
padding: 10px;
width: 50%;
float: left;
}
#language-list {
padding: 10px;
width: 50%px;
float: left;
}
table thead {
font-weight: bold;
}
table td {
padding: 5px;
}<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<link rel="stylesheet" type="text/css" href="//cdn.sstatic.net/codegolf/all.css?v=83c949450c8b">
<div id="answer-list">
<h2>Leaderboard</h2>
<table class="answer-list">
<thead>
<tr><td></td><td>Author</td><td>Language</td><td>Size</td></tr>
</thead>
<tbody id="answers">
</tbody>
</table>
</div>
<div id="language-list">
<h2>Winners by Language</h2>
<table class="language-list">
<thead>
<tr><td>Language</td><td>User</td><td>Score</td></tr>
</thead>
<tbody id="languages">
</tbody>
</table>
</div>
<table style="display: none">
<tbody id="answer-template">
<tr><td>{{PLACE}}</td><td>{{NAME}}</td><td>{{LANGUAGE}}</td><td>{{SIZE}}</td><td><a href="{{LINK}}">Link</a></td></tr>
</tbody>
</table>
<table style="display: none">
<tbody id="language-template">
<tr><td>{{LANGUAGE}}</td><td>{{NAME}}</td><td>{{SIZE}}</td><td><a href="{{LINK}}">Link</a></td></tr>
</tbody>
</table>
0.7734pour bonjour ou serait.7734acceptable?0.7734est requisoligonécessite un zéro de fin après la décimale:0.6170Réponses:
CJam,
4442 octetsEssayez-le en ligne dans l' interprète CJam .
Pour exécuter le programme à partir de la ligne de commande, téléchargez l' interpréteur Java et exécutez:
Comment ça marche
la source
Bash + coreutils, 54
Encore une fois, merci à @TobySpeight pour l'aide au golf.
La liste de mots d'entrée est tirée de STDIN:
la source
Python 2,
271216211205 OctetsC'est la seule idée que j'ai eue jusqu'à présent .. Je mettrai à jour ceci une fois que je penserai à autre chose! J'ai supposé que nous devions lire un fichier, mais sinon, faites-le moi savoir pour que je puisse mettre à jour :)
Un grand merci à Dennis pour m'avoir sauvé 55 octets :)
Merci aussi à Sp3000 pour avoir économisé 6 octets :)
la source
"oizehsglb".index(b)plus court?d[b] == "oizehsglb".index(b). Il manque peut-être un transtypage en chaîne / caractère..findest plus court que.index, 2) Selon la version que vous possédez, au moins en 2.7.10opensans argument de mode par défautr, 3) Ne fonctionne pas seulementfor x in open(...)? (il peut être nécessaire de supprimer une nouvelle ligne de fin) Si ce n'est pas le cas, alors.split('\n')est plus court que.splitlines()g+=[['0.'+c[1:],c][c[0]!='0']]*c.isdigit(), et vous pouvez en économiser un peu plus en inversantfpuis en faisantfor c in fau lieu d'avoirc=x[::-1]. De plus, vous ne l'utilisezfqu'une seule fois, vous n'avez donc pas besoin de l'enregistrer en tant que variableJavaScript (ES7), 73 octets
Cela peut être fait dans ES7 avec seulement 73 octets:
Ungolfed:
Usage:
Une fonction:
J'ai exécuté cela sur la liste de mots UNIX et j'ai mis les résultats dans une corbeille à pâte:
Résultats
Le code utilisé pour obtenir les résultats sur Firefox :
la source
t('Impossible')?Python 2, 121 octets
Suppose que le fichier de dictionnaire
w.txtse termine par un retour à la ligne de fin et n'a pas de lignes vides.la source
GNU sed, 82
(dont 1 pour
-r)Merci à @TobySpeight pour l'aide au golf.
La liste de mots d'entrée est tirée de STDIN:
la source
TI-BASIC,
7588 octetsedit 2: peu importe, c'est toujours techniquement invalide, car il n'accepte qu'un seul mot à la fois (pas un dictionnaire). Je vais essayer de le corriger pour autoriser plus d'un mot en entrée ...
modifier: oups; À l'origine, je l'ai fait afficher un .0 à la fin si le dernier nombre était 0, et non l'inverse. Corrigé, bien que ce soit une mauvaise solution de contournement (affiche "0" à côté du nombre s'il commence par 0, sinon affiche deux espaces au même endroit). Du bon côté, il gère correctement des mots comme "Otto" (affiche les deux 0) car il n'affiche pas réellement un nombre décimal!
Je ne peux pas penser à une meilleure langue pour le faire. Peut certainement être plus joué au golf, mais je suis trop fatigué en ce moment. Le tilde est le symbole de négation [le ( - )bouton].
L'entrée est tirée de la variable de réponse de la calculatrice, ce qui signifie ce qui a été évalué pour la dernière fois (comme
_dans le shell python interactif), vous devez donc taper une chaîne sur l'écran d'accueil (le guillemet est activé ALPHA+), appuyez sur ENTER, puis exécutez le programme. Alternativement, vous pouvez utiliser deux points pour séparer les commandes, donc si vous nommez le programme, par exemple, "CALCTEXT" et que vous souhaitez l'exécuter sur la chaîne "HELLO", vous pouvez taper"HELLO":prgmCALCTEXTau lieu de les faire séparément.la source
Python 2,
147158156 156 octetsJe manquais ce «0». exigence. J'espère que ça marche bien.
edit : Suppression de ".readlines ()" et cela fonctionne toujours; p
edit2 : Suppression de certains espaces et déplacement de l'impression vers la 3e ligne
edit3 : Sauvegardé 2 octets grâce à Sp3000 (espace supprimé après impression et changé 'index' en 'find')
la source
Python 2,
184174 octetsla source
Rubis 2,
8886 octetsLe nombre d'octets comprend 2 pour les
lnoptions de la ligne de commande:la source
==""peut être remplacé par<?A. Et pas besoingsub()commesub()ça suffit.C,
182172169 169/181172 octetsÉtendu
en utilisant les mots liés.txt, avec une conversion en minuscules:
la source
*s|32fonctionnera pas comme conversion minuscule dans ce contexte?Haskell, 175 octets sans importations (229 octets avec importations)
Code pertinent (par exemple dans le fichier Calc.hs):
la source
Java,
208200176 octetsÉtendu
Il ajoute toujours la décimale, et quand invalide retourne ".". Mais sinon, ça fonctionne comme il se doit. : P
Merci @ LegionMammal978!
la source
;String l=vers,l=et=o+vers+=.