J'ai récemment fait mes devoirs où j'ai dû apprendre un modèle pour la classification à 10 chiffres du MNIST. Le HW avait un code d'échafaudage et j'étais censé travailler dans le contexte de ce code.
Mes devoirs fonctionnent / réussissent les tests, mais maintenant j'essaie de tout faire à partir de zéro (mon propre framework nn, pas de code d'échafaudage hw) et je suis bloqué en appliquant le grandient de softmax à l'étape backprop, et je pense même à ce que le hw le code d'échafaudage n'est peut-être pas correct.
Le hw m'a fait utiliser ce qu'ils appellent «une perte softmax» comme dernier nœud du nn. Ce qui signifie, pour une raison quelconque, qu'ils ont décidé de joindre une activation softmax avec la perte d'entropie croisée tout en un, au lieu de traiter la softmax comme une fonction d'activation et l'entropie croisée comme une fonction de perte distincte.
Le func hw loss ressemble alors à ceci (édité au minimum par moi):
class SoftmaxLoss:
"""
A batched softmax loss, used for classification problems.
input[0] (the prediction) = np.array of dims batch_size x 10
input[1] (the truth) = np.array of dims batch_size x 10
"""
@staticmethod
def softmax(input):
exp = np.exp(input - np.max(input, axis=1, keepdims=True))
return exp / np.sum(exp, axis=1, keepdims=True)
@staticmethod
def forward(inputs):
softmax = SoftmaxLoss.softmax(inputs[0])
labels = inputs[1]
return np.mean(-np.sum(labels * np.log(softmax), axis=1))
@staticmethod
def backward(inputs, gradient):
softmax = SoftmaxLoss.softmax(inputs[0])
return [
gradient * (softmax - inputs[1]) / inputs[0].shape[0],
gradient * (-np.log(softmax)) / inputs[0].shape[0]
]
Comme vous pouvez le voir, en avant, il fait softmax (x), puis traverse la perte d'entropie.
Mais sur backprop, il semble ne faire que la dérivée de l'entropie croisée et non du softmax. Softmax est laissé tel quel.
Ne devrait-il pas également prendre la dérivée de softmax par rapport à l'entrée de softmax?
En supposant qu'il devrait prendre le dérivé de softmax, je ne sais pas comment ce hw passe réellement les tests ...
Maintenant, dans ma propre implémentation à partir de zéro, j'ai fait des nœuds séparés softmax et entropie croisée, comme ça (p et t représentent prédit et vérité):
class SoftMax(NetNode):
def __init__(self, x):
ex = np.exp(x.data - np.max(x.data, axis=1, keepdims=True))
super().__init__(ex / np.sum(ex, axis=1, keepdims=True), x)
def _back(self, x):
g = self.data * (np.eye(self.data.shape[0]) - self.data)
x.g += self.g * g
super()._back()
class LCE(NetNode):
def __init__(self, p, t):
super().__init__(
np.mean(-np.sum(t.data * np.log(p.data), axis=1)),
p, t
)
def _back(self, p, t):
p.g += self.g * (p.data - t.data) / t.data.shape[0]
t.g += self.g * -np.log(p.data) / t.data.shape[0]
super()._back()
Comme vous pouvez le voir, ma perte d'entropie croisée (LCE) a la même dérivée que celle du hw, car c'est la dérivée de la perte elle-même, sans entrer dans le softmax pour le moment.
Mais alors, je devrais encore faire le dérivé de softmax pour l'enchaîner avec le dérivé de perte. C'est là que je suis coincé.
Pour softmax défini comme:
Le dérivé est généralement défini comme:
Mais j'ai besoin d'un dérivé qui se traduit par un tenseur de la même taille que l'entrée de softmax, dans ce cas, batch_size x 10. Je ne sais donc pas comment appliquer ce qui précède à seulement 10 composants, car cela implique que je se différencierait pour toutes les entrées par rapport à toutes les sorties (toutes les combinaisons) ou sous forme matricielle.
la source
Réponses:
Après avoir travaillé plus avant sur ce sujet, j'ai compris que:
L'implémentation des devoirs combine softmax avec perte d'entropie croisée par choix, tandis que mon choix de garder softmax séparé en tant que fonction d'activation est également valide.
L'implémentation des devoirs manque en effet la dérivée de softmax pour la passe backprop.
Le gradient de softmax par rapport à ses entrées est vraiment le partiel de chaque sortie par rapport à chaque entrée:
Donc, pour la forme vectorielle (gradient):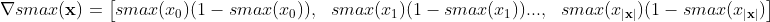
Lequel dans mon code numpy vectorisé est simplement:
Où
self.dataest le softmax de l'entrée, précédemment calculé à partir de la passe avant.la source